Deep dive into the most complex Neural Network till now.

Prerequisites before you start with this article:
Introduction
Transformers are the predominant architecture in most cutting-edge NLP applications today such as BERT, MUM, and GPT-3. In this article, I will be explaining the transformer architecture in detail.
The game-changer part for the sequencer data was developed when we came up with something called Transformers and this paper was something which is based on a concept called Attention.
As per Wikipedia, A Transformer is a deep learning model that adopts the mechanism of attention, differentially weighing the significance of each part of the input data. It is used primarily in the field of natural language processing (NLP) and in computer vision (CV).
A transformer is built using an encoder and decoder and both are comprised of modules that can speak onto the top of each other multiple times. So what happens is the inputs and outputs are first embedded into n-dimension space, since we cannot use this directly. So we obviously have to encode our inputs, whatever we are providing. One slight, but important part of this model is the positional and coding of different words. Since we have no recurrent neural network that can remember how to sequence is fed into the model, we need to somehow give every word or part of a sequence, a relative position since a sequence depends on the order of the elements. These positions are added to the embedded representation of each word.
Like RNNs/LSTMs, Transformers is an architecture for transforming one sequence into an antidote while helping the other two parts that is encoders and decoders, but it differs from the previously described sequence of your sequence model because it does not work like GRUs. So it does not implement recurring neural networks. Recurrent neural network until now was one of the best ways to capture the tiny dependence on a sequence. However, the team presenting this paper that is ‘Attention Is All You Need’ prove that architecture with only an attention mechanism that does not use RNN can improve its result in translation task and other NLP tasks.
However, unlike RNNs/LSTMs, transformers do not necessarily process the data in order. Rather, the attention mechanism provides context for any position in the input sequence. For example, if the input data is a natural language sentence, the transformer does not need to process the beginning of the sentence before the end. Rather, it identifies the context that confers meaning to each word in the sentence. This feature allows for more parallelization than RNNs and therefore reduces training times.
What do Transformers do?
Transformers are the current state-of-the-art type of model for dealing with sequences. Perhaps the most prominent application of these models is in text processing tasks, and the most prominent of these is a machine translation. In fact, transformers and their conceptual descendants have penetrated just about every benchmark leaderboard in Natural Language Processing (NLP), from question answering to grammar correction. In many ways, transformer architectures are undergoing a surge in development similar to what we saw with Convolutional Neural Networks(CNN) following the 2012 ImageNet competition, for better and for worse.
The transformer can be understood in terms of its three components:
An Encoder that encodes an input sequence into state representation vectors.
An Attention mechanism that enables our Transformer model to focus on the right aspects of the sequential input stream. This is used repeatedly within both the encoder and the decoder to help them contextualize the input data.
A Decoder that decodes the state representation vector to generate the target output sequence.
Transformer Architecture

The Transformer Architecture. Credits
In a nutshell, the task of the encoder, on the left half of the Transformer architecture, is to map an input sequence to a sequence of continuous representations, which is then fed into a decoder.
The decoder, on the right half of the architecture, receives the output of the encoder together with the decoder output at the previous time step, to generate an output sequence.
Encoder
The Encoder stack is composed of a stack of 6 identical layers(Encoder#1, Encoder#2, Encoder#3........Encoder#6).

One Single Encoder block. Credits
Each layer has two sub-layers. The first is a multi-head self-attention mechanism, and the second is a simple, position-wise fully connected feed-forward network. We employ a residual connection around each of the two sub-layers, followed by layer normalization.
That is, the output of each sub-layer is:
LayerNorm(x + Sublayer(x)),
where Sublayer(x) is the function implemented by the sub-layer itself.
To facilitate these residual connections, all sub-layers in the model, as well as the embedding layers, produce outputs of dimension dmodel = 512.
The Add and Normalization layer takes the outputs from the multi-head attention block, adds them together, and normalizes the result with layer normalization. If you have heard of batch normalization, layer normalization is similar but instead of normalizing the input features across the batch dimensions, it normalizes the inputs to a layer across all features.
One slight but important part of the model is the positional encoding of the different words. Since we have no recurrent networks that can remember how sequences are fed into a model, we need to somehow give every word/part in our sequence a relative position since a sequence depends on the order of its elements. These positions are added to the embedded representation (n-dimensional vector) of each word.
The positional encoding blocks inject information about the position of each word vector by concatenating sine and cosine functions of different wavelengths/frequencies to these vectors as demonstrated in the equations below.

Equations for sine and cosine positional embeddings
Given the equations above, if we consider an input with 10,000 possible positions, the positional encoding block will add sine and cosine values with wavelengths that increase geometrically from 2𝝅 to 10000*2𝝅. This allows us to mathematically represent the relative position of word vectors such that a neural network can learn to recognize differences in position.
Decoder
The decoder is also composed of a stack of 6 identical layers(Decoder#1, Decoder#2, Decoder#3........Decoder#6).

One Single Decoder block. Credits
In addition to the two sub-layers in each encoder layer, the decoder inserts a third sub-layer, which performs multi-head attention over the output of the encoder stack. Similar to the encoder, we employ residual connections around each of the sub-layers, followed by layer normalization. We also modify the self-attention sub-layer in the decoder stack to prevent positions from attending to subsequent positions. This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position i can depend only on the known outputs at positions less than II.
Let us just consider a single block of Encoder and Decoder:

Single blocks of Encoder and Decoder. Credits
Self-attention in Encoder looks at an input sequence and decides at each step which other parts of the sequence are important, while the Encoder-Decoder attention in decoder helps it to focus on relevant parts of the input sequence(same as what we have in seq2seq models).
Self-attention
Say the following sentence is an input sentence we want to translate:
”The animal didn't cross the street because it was too tired.”
What does “it” in this sentence refer to? Is it referring to the street or to the animal? It’s a simple question to a human, but not as simple to an algorithm.
When the model is processing the word “it”, self-attention allows it to associate “it” with “animal”.
As the model processes each word (each position in the input sequence), self-attention allows it to look at other positions in the input sequence for clues that can help lead to a better encoding for this word.
If you’re familiar with RNNs, think of how maintaining a hidden state allows an RNN to incorporate its representation of previous words/vectors it has processed with the current one it’s processing. Self-attention is the method the Transformer uses to bake the “understanding” of other relevant words into the one we’re currently processing.

As we are encoding the word "it" in encoder #5 (the top encoder in the stack), part of the attention mechanism was focusing on "The Animal", and baked a part of its representation into the encoding of "it". Credits
How to Calculate self-attention?
The first step in calculating self-attention is to create three vectors from each of the encoder’s input vectors (in this case, the embedding of each word). So for each word, we create a Query vector, a Key vector, and a Value vector.
These vectors are created by multiplying the embedding by three matrices that we trained during the training process.

Q is a matrix that contains the query (vector representation of one word in the sequence), K are all the keys (vector representations of all the words in the sequence) and
V are the values, which are again the vector representations of all the words in the sequence.
For the encoder and decoder, multi-head attention modules, V consists of the same word sequence as Q. However, for the attention module that is taking into account the encoder and the decoder sequences, V is different from the sequence represented by Q.
To simplify this a little bit, we could say that the values in V are multiplied and summed with some attention-weights a, where our weights are defined by:

This means that the weights a are defined by how each word of the sequence (represented by Q) is influenced by all the other words in the sequence (represented by K). Additionally, the SoftMax function is applied to the weights a to have a distribution between 0 and 1. Those weights are then applied to all the words in the sequence that are introduced in V (same vectors than Q for encoder and decoder but different for the module that has encoder and decoder inputs).

The righthand picture shows multi-head attention which explains how this attention mechanism can be parallelized into multiple mechanisms that can be used side by side. The attention mechanism is repeated multiple times with linear projections of Q, K, and V. This allows the system to learn from different representations of Q, K, and V, which is beneficial to the model. These linear representations are done by multiplying Q, K, and V by weight matrices W that are learned during the training.
Those matrices Q, K, and V are different for each position of the attention modules in the structure depending on whether they are in the encoder, decoder or in-between encoder and decoder. The reason is that we want to attend on either the whole encoder input sequence or a part of the decoder input sequence. The multi-head attention module that connects the encoder and decoder will make sure that the encoder input-sequence is taken into account together with the decoder input-sequence up to a given position.
After the multi-attention heads in both the encoder and decoder, we have a pointwise feed-forward layer. This little feed-forward network has identical parameters for each position, which can be described as a separate, identical linear transformation of each element from the given sequence.

A more lucid representation of the Transformer architecture
Now let's look at the decoder side:
The output of the top encoder is transformed into a set of (K, V) attention vectors. They are given as input to each decoder in its Encoder-Decoder Attention layer which helps the decoder focus on appropriate places in the input sequence.
The decoding continues until <EOS> is reached, indicating the transformer decoder has completed its output. The output of each step is fed to the bottom of the next decoder in the next time step, and the decoders bubble up their decoding results just like encoders did. And just like we did in encoders input, we embed and add positional encoding to those decoder inputs to indicate the position of each word.
The self-attention layers in the decoder operate in a slightly different way than the ones in the encoder:
In the decoder, the self-attention layer is only allowed to attend to earlier positions in the output sequence. This is done by masking future positions (setting them to -inf) before the softmax step in the self-attention calculation.
The “Encoder-Decoder Attention” layer works just like multiheaded self-attention, except it creates its Queries matrix from the layer below it, and takes the Keys and Values matrix from the output of the encoder stack.
The Final Linear and Softmax Layer
The decoder stack outputs a vector of floats points digits. How do we convert that into a word? This is done by the final Linear layer which is followed by a Softmax Layer.
The Linear layer is a simple fully connected neural network that projects the vector produced by the stack of decoders, into a much, much larger vector called a logits vector.
Let’s assume that our model knows 10,000 unique English words (our model’s “output vocabulary”) that it’s learned from its training dataset. This would make the logits vector 10,000 cells wide – each cell corresponding to the score of a unique word. That is how we interpret the output of the model followed by the Linear layer.
The softmax layer then turns those scores into probabilities (all positive, all add up to 1.0). The cell with the highest probability is chosen, and the word associated with it is produced as the output for this time step.
Training Transformer
During training, an untrained model would go through the exact same forward pass. But since we are training it on a labeled training dataset, we can compare its output with the actual correct output.
To visualize this, let’s assume our output vocabulary only contains six words(“a”, “am”, “i”, “thanks”, “student”, and “<eos>” (short for ‘end of sentence’)).
Once we define our output vocabulary, we can use a vector of the same width to indicate each word in our vocabulary. This is also known as one-hot encoding. So for example, we can indicate the word “am” using the following vector:

Following this recap, let’s discuss the model’s loss function – the metric we are optimizing during the training phase to lead up to a trained and hopefully amazingly accurate model.
The Loss Function
Say we are training our model. Say it’s our first step in the training phase, and we’re training it on a simple example – translating “merci” into “thanks”.
What this means, is that we want the output to be a probability distribution indicating the word “thanks”. But since this model is not yet trained, that’s unlikely to happen just yet.

Since the model's parameters (weights) are all initialized randomly, the (untrained) model produces a probability distribution with arbitrary values for each cell/word. We can compare it with the actual output, then tweak all the model's weights using backpropagation to make the output closer to the desired output.
How do you compare two probability distributions?
We simply use cross-entropy and Kullback–Leibler divergence. Read here.
More realistically, we’ll use a sentence longer than one word. For example – input: “je suis étudiant” and expected output: “i am a student”. What this really means, is that we want our model to successively output probability distributions where:
Each probability distribution is represented by a vector of width vocab_size (6 in our toy example, but more realistically a number like 30,000 or 50,000)
The first probability distribution has the highest probability at the cell associated with the word “i”
The second probability distribution has the highest probability at the cell associated with the word “am”
And so on, until the fifth output distribution indicates ‘<end of sentence>’ symbol, which also has a cell associated with it from the 10,000 element vocabulary.
After training the model for enough time on a large enough dataset, we would hope the produced probability distributions would look like this:
Now, because the model produces the outputs one at a time, we can assume that the model is selecting the word with the highest probability from that probability distribution and throwing away the rest. That’s one way to do it (called greedy decoding). Another way to do it would be to hold on to, say, the top two words (say, ‘I’ and ‘a’ for example), then in the next step, run the model twice: once assuming the first output position was the word ‘I’, and another time assuming the first output position was the word ‘a’, and whichever version produced less error considering both positions #1 and #2 is kept. We repeat this for positions #2 and #3…etc. This method is called “beam search”, wherein our example, beam_size was two (meaning that at all times, two partial hypotheses (unfinished translations) are kept in memory), and top_beams is also two (meaning we’ll return two translations). These are both hyperparameters that you can experiment with.
Inference
Inferring with those models is different from the training, which makes sense because in the end, we want to translate a French sentence without having the German sentence. The trick here is to re-feed our model for each position of the output sequence until we come across an end-of-sentence token.
A step by step method would be:
Input the full encoder sequence (French sentence) and as decoder input, we take an empty sequence with only a start-of-sentence token on the first position. This will output a sequence where we will only take the first element.
That element will be filled into the second position of our decoder input sequence, which now has a start-of-sentence token and a first word/character in it.
Input both the encoder sequence and the new decoder sequence into the model. Take the second element of the output and put it into the decoder input sequence.
Repeat this until you predict an end-of-sentence token, which marks the end of the translation.
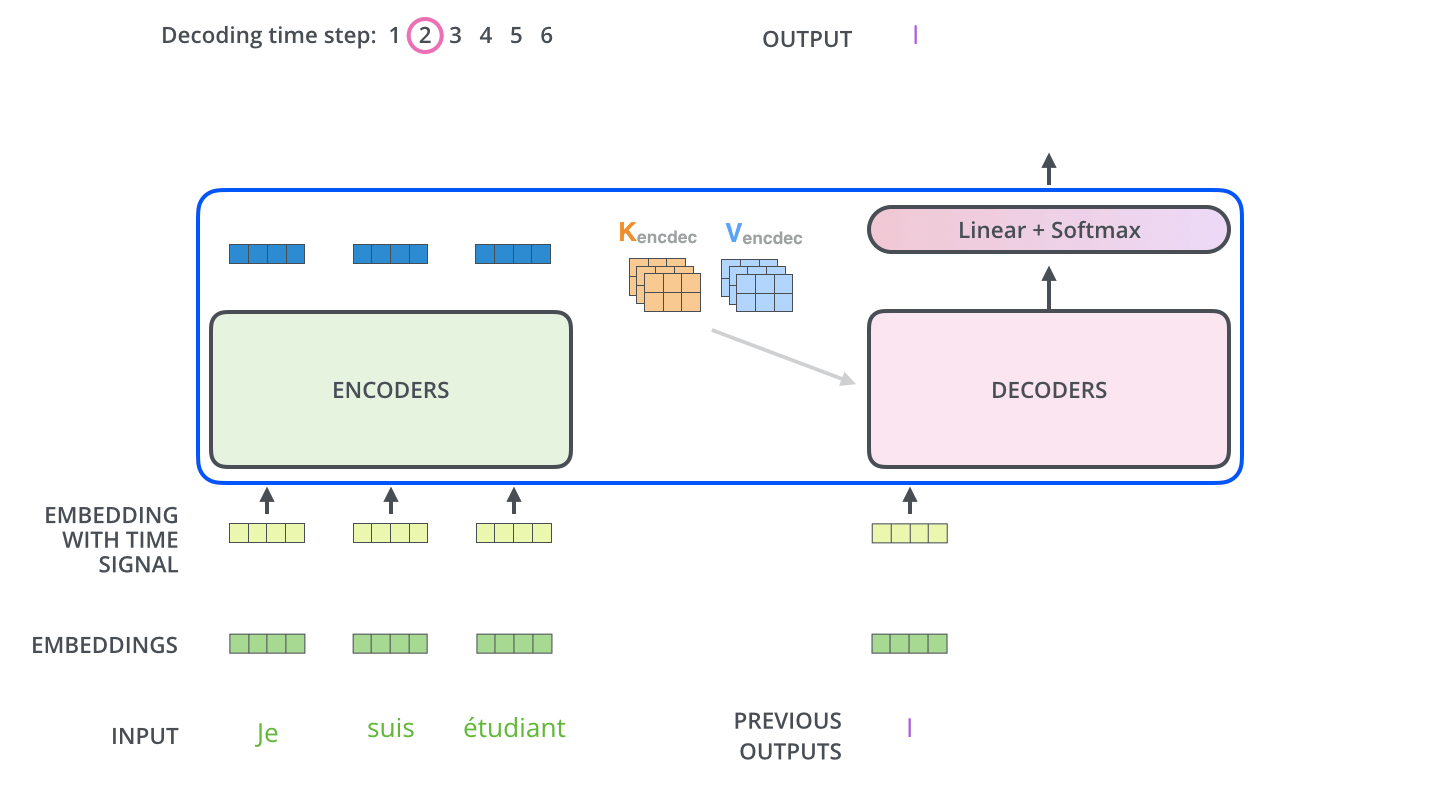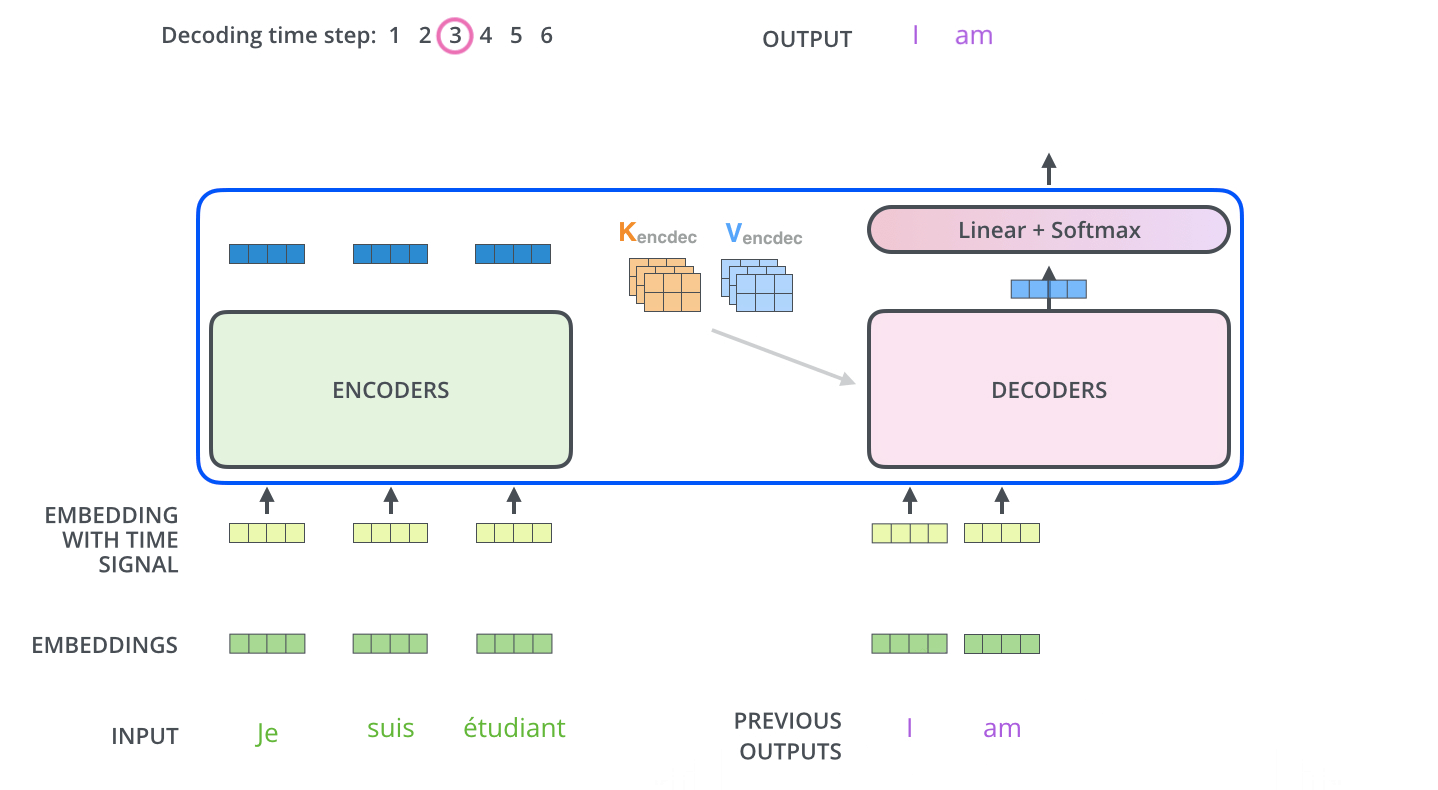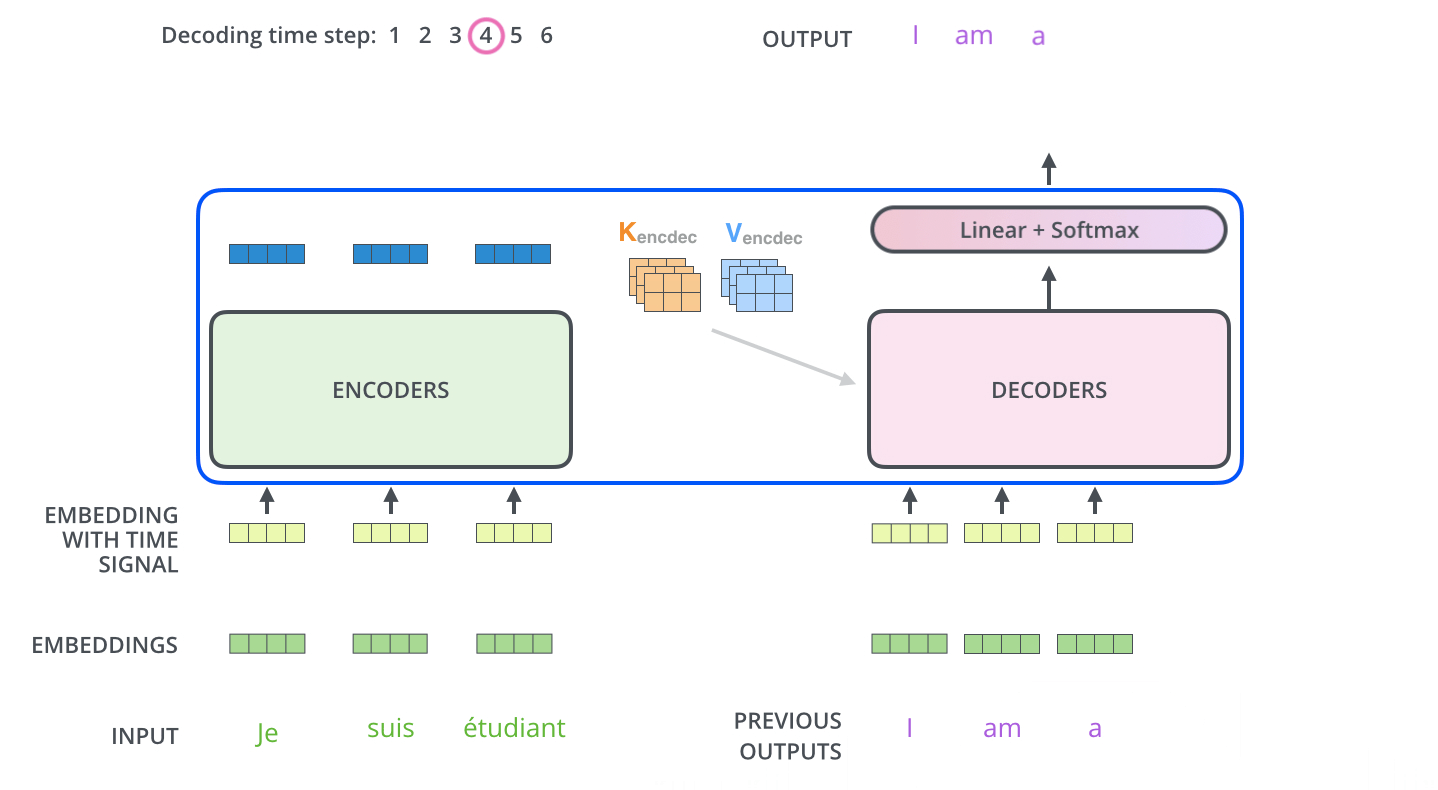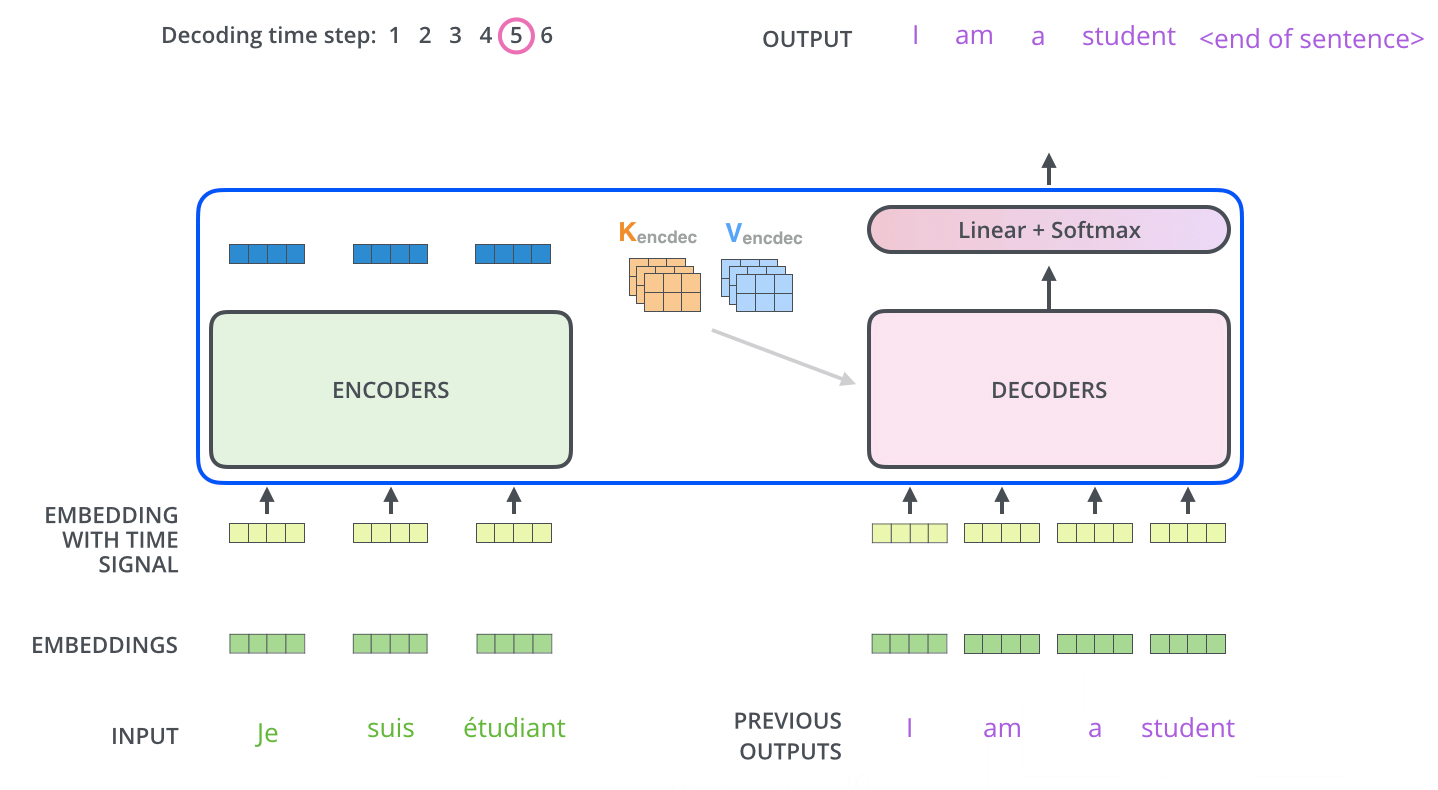
We see that we need multiple runs through our model to translate our sentences.
I hope that these descriptions have made the Transformer architecture a little bit clearer for everybody starting with Seq2Seq and encoder-decoder structures.