
Credits: https://expertsystem.com/natural-language-processing-sentiment-analysis/
Discovering customer sentiments with Natural Language Processing using Apache Spark
In the first blog(Natural language processing in Apache Spark using NLTK (part 1/2)) of this 2 blog series I have discussed Natural Language Processing, NLTK in Spark, environment setup and some basic implementations like Word tokenization, Stopwords removal, Part of speech tagging, Named Entity Recognition, Lemmatization and Text Classification. Now in this blog, I’ll draw sentiments from customer reviews of one product from the concepts of Natural Language Processing using NLTK in Apache Spark.
Understanding customer feedback gets harder and harder at a greater scale and with a greater variety of channels through which customers can provide feedback. Businesses that seek to better grasp the sentiments of their customers might have to sift through thousands of messages in order to get a feel for what customers are saying about their products or services.
In order to save time and resources, businesses might look to automation that can quantify customer feedback from channels such as chat messages, emails, call center recordings, and social media comments in real-time. Natural language processing (NLP) may help some businesses with a high volume of customer feedback garner insights from it in the form of quantifiable trends, or in other words, increases and decreases in the frequency of specific customer complaints.

So in this blog, I will be discussing how we can process user reviews of any product and extract some meaningful insights which could be helpful in taking complex business decisions, let’s talk about Amazon Alexa. Amazon Alexa, known simply as Alexa,[2] is a virtual assistant developed by Amazon, first used in the Amazon Echo and the Amazon Echo Dot smart speakers developed by Amazon Lab126. It is capable of voice interaction, music playback, making to-do lists, setting alarms, streaming podcasts, playing audiobooks, and providing weather, traffic, sports, and other real-time information, such as news.
I have downloaded the Alexa user review sample dataset from Kaggle.
Click this link to download the sample data. Our dataset will look something like this which is purely an unstructured format. So here we’ll also learn how to process unstructured text data with ease.
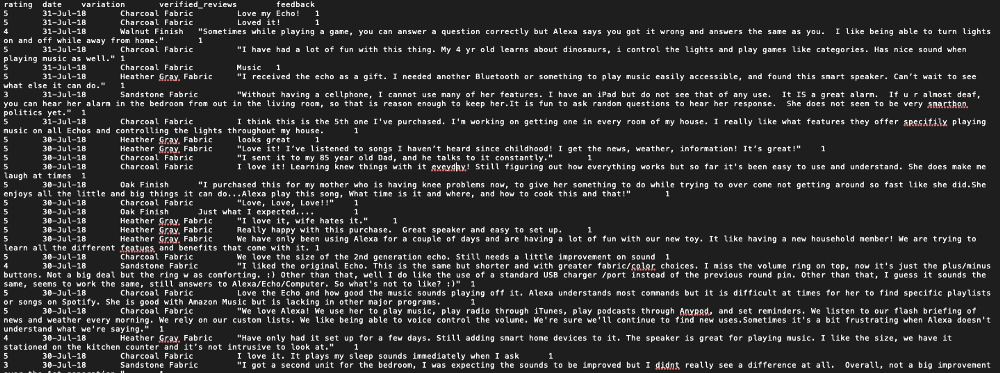
Sample review data
So the dataset contains 5 columns namely: rating, date, variation, verified_reviews, feedback.
rating: Ratings given by the customers out of 5.
date: Date of publishing the review.
variation: Category.
verified_reviews: Comments given by the users.
feedback: 1 for positive response and 0 for the negative response.
Using the above dataset, we will perform some analysis and will draw out some insights, like :
Extract key phrases and determine user sentiments(positive, negative or neutral).
Find out the top 20 keywords from the review given by the users.
Also, I’m going to plot the result like bar-graph etc.
This post will help you to understand how to handle data sets that do not have a proper structure.
Steps I will follow : 1. download data in any format, in my case its a .tsv file 2. creating schema 3. data processing using my spark 4. visualize the output
Environment details :
Python 2.7
Jupyter notebook(connected with Apache Spark)
Apache Spark 2.x
Lets start coding
Load all the required libraries.
from pyspark import SparkContext
from pyspark.sql.types import *
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, lit
from functools import reduce
import nltk
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import pandas as pd
import re
import stringStep 1: Create spark session and provide master as yarn-client and provide application name.
spark = SparkSession.builder.master('yarn-client').appName('Amazon_Alexa_User_Review').getOrCreate()Step 2: Load amazon_alexa.tsv(TSV stands for Tab Separated Values) data into spark data frame from HDFS.
schema = StructType([
StructField("rating", IntegerType(), True),
StructField("date", StringType(), True),
StructField("variation", StringType(), True),
StructField("verified_reviews", StringType(), True),
StructField("feedback", IntegerType(), True)])data = spark.read.format("org.apache.spark.csv").option("delimiter","\t").schema(schema).option("mode", "PERMISSIVE").option("inferSchema", "True").csv(''hdfs:///user/spark/warehouse/amazon_alexa.tsv')data.createOrReplaceTempView("data")Our data is now stored in the data frame “data”. And this is how it looks after we have stored the TSV data in the spark data frame.
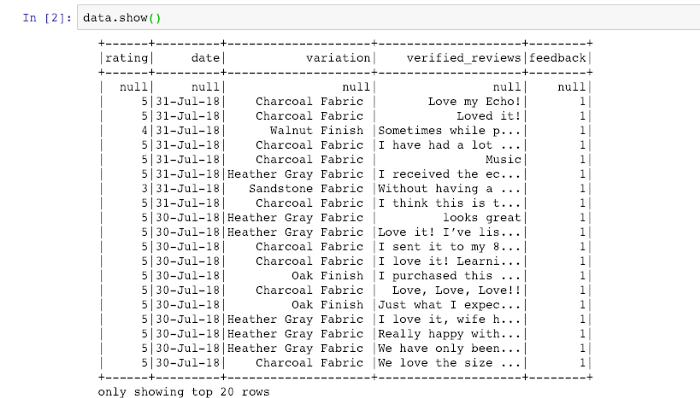
Output
Step 3: Fetch column: “verified_reviews” because we need only that column for extracting sentiments from customers and for that we need to convert our data frame into RDD(best suited for processing unstructured data).
reviews_rdd = data.select("verified_reviews").rdd.flatMap(lambda x: x)
reviews_rdd.collect()
Output
Step 4: Remove the header and convert all the data into lowercase for easy processing.
header = reviews_rdd.first()
data_rmv_col = reviews_rdd.filter(lambda row: row != header)
lowerCase_sentRDD = data_rmv_col.map(lambda x : x.lower())Step 5: Text data can be split into sentences and this process is called sentence tokenization.
def sent_TokenizeFunct(x):
return nltk.sent_tokenize(x)sentenceTokenizeRDD = lowerCase_sentRDD.map(sent_TokenizeFunct)
Output
Step 6: Now split each sentence into words, also called word tokenization.
def word_TokenizeFunct(x):
splitted = [word for line in x for word in line.split()]
return splittedwordTokenizeRDD = sentenceTokenizeRDD.map(word_TokenizeFunct)
Output
Step 7: To move ahead first we will clean our data, here we’re gonna remove stopwords, punctuations, and empty spaces.
def removeStopWordsFunct(x):
from nltk.corpus import stopwords
stop_words=set(stopwords.words('english'))
filteredSentence = [w for w in x if not w in stop_words]
return filteredSentencestopwordRDD = words1.map(removeStopWordsFunct)
def removePunctuationsFunct(x):
list_punct=list(string.punctuation)
filtered = [''.join(c for c in s if c not in list_punct) for s in x]
filtered_space = [s for s in filtered if s] #remove empty space
return filteredrmvPunctRDD = stopwordRDD.map(removePunctuationsFunct)
Output
Step 8: Lemmatization
Stemming and Lemmatization are the basic text processing methods for English text. The goal of both of them is to reduce inflectional forms and sometimes derivationally related forms of a word to a common base form. I have skipped Stemming because it is not an efficient method as sometimes it produces words that are not even close to the actual word.
def lemmatizationFunct(x):
nltk.download('wordnet')
lemmatizer = WordNetLemmatizer()
finalLem = [lemmatizer.lemmatize(s) for s in x]
return finalLemlem_wordsRDD = rmvPunctRDD.map(lemmatizationFunct)Step 9: Our next task is a little tricky, we have to extract keyphrases(also called Noun phrases). So first we need to join “lem_wordsRDD” tokens.
def joinTokensFunct(x):
joinedTokens_list = []
x = " ".join(x)
return xjoinedTokens = lem_wordsRDD.map(joinTokensFunct)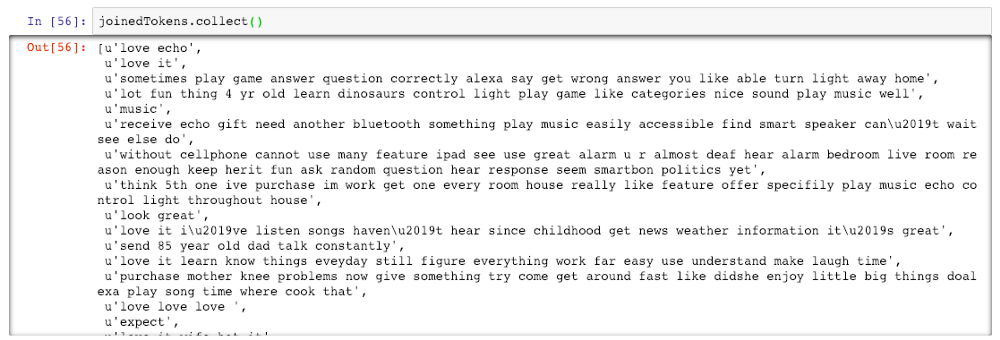
Output
Step 10: Extract key phrases
In the below code I’m doing chunking, chinking, and POS tagging using Regular expression and extracting all the Noun phrases.
Chunking: Also referred to as shallow parsing, is a task that follows Part-Of-Speech Tagging and that adds more structure to the sentence. The result is a grouping of the words in “chunks”.
Chinking: Chinking is a lot like chunking, it is basically a way for you to remove a chunk from a chunk. The chunk that you remove from your chunk is your chink.
POS tagging: A Part-Of-Speech Tagger (POS Tagger) is a piece of software that reads the text in some language and assigns parts of speech to each word (and other tokens), such as noun, verb, adjective, etc.
def extractPhraseFunct(x):
from nltk.corpus import stopwords
stop_words=set(stopwords.words('english')) def leaves(tree):
"""Finds NP (nounphrase) leaf nodes of a chunk tree."""
for subtree in tree.subtrees(filter = lambda t: t.label()=='NP'):
yield subtree.leaves()
def get_terms(tree):
for leaf in leaves(tree):
term = [w for w,t in leaf if not w in stop_words]
yield termsentence_re = r'(?:(?:[A-Z])(?:.[A-Z])+.?)|(?:\w+(?:-\w+)*)|(?:\$?\d+(?:.\d+)?%?)|(?:...|)(?:[][.,;"\'?():-_`])'
grammar = r"""
NBAR:
{<NN.*|JJ>*<NN.*>} # Nouns and Adjectives, terminated with Nouns
NP:
{<NBAR>}
{<NBAR><IN><NBAR>} # Above, connected with in/of/etc...
"""
chunker = nltk.RegexpParser(grammar)
tokens = nltk.regexp_tokenize(x,sentence_re)
postoks = nltk.tag.pos_tag(tokens) #Part of speech tagging
tree = chunker.parse(postoks) #chunking
terms = get_terms(tree)
temp_phrases = []
for term in terms:
if len(term):
temp_phrases.append(' '.join(term))
finalPhrase = [w for w in temp_phrases if w] #remove empty lists
return finalPhraseextractphraseRDD = joinedTokens.map(extractPhraseFunct)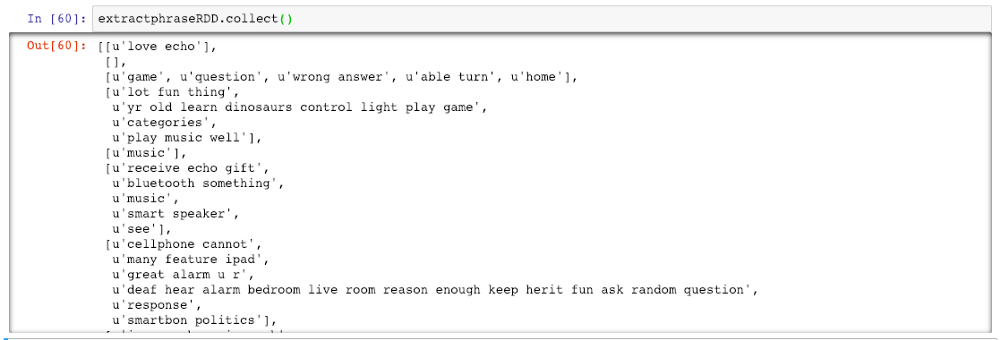
Output
Step 11: From the above step we roughly got all the key phrases the customers are talking about. Now categorize these key phrases into Positive, Negative, or Neutral.
There are so many ways to get the sentiments, I’m using NLTK VADER you guys can choose any other method as per your interest.
def sentimentWordsFunct(x):
from nltk.sentiment.vader import SentimentIntensityAnalyzer
analyzer = SentimentIntensityAnalyzer()
senti_list_temp = [] for i in x:
y = ''.join(i)
vs = analyzer.polarity_scores(y)
senti_list_temp.append((y, vs))
senti_list_temp = [w for w in senti_list_temp if w] sentiment_list = []
for j in senti_list_temp:
first = j[0]
second = j[1]
for (k,v) in second.items():
if k == 'compound':
if v < 0.0:
sentiment_list.append((first, "Negative"))
elif v == 0.0:
sentiment_list.append((first, "Neutral"))
else:
sentiment_list.append((first, "Positive")) return sentiment_listsentimentRDD = extractphraseRDD.map(sentimentWordsFunct)
Output
Step 12: Now let's extract the top 20 keywords from the extracted key phrases.
freqDistRDD = extractphraseRDD.flatMap(lambda x : nltk.FreqDist(x).most_common()).map(lambda x: x).reduceByKey(lambda x,y : x+y).sortBy(lambda x: x[1], ascending = False)
Output
Step 13: Visualizing the output. I’m using the function pandD.plot.barh() to visualize the output. Click this to see all available graphs that can be used instead of a horizontal bar graph(barh).
df_fDist = freqDistRDD.toDF() #converting RDD to spark dataframe
df_fDist.createOrReplaceTempView("myTable")
df2 = spark.sql("SELECT _1 AS Keywords, _2 as Frequency from myTable limit 20") #renaming columns
pandD = df2.toPandas() #converting spark dataframes to pandas dataframes
pandD.plot.barh(x='Keywords', y='Frequency', rot=1, figsize=(10,8))
Visual representation
Let us create a word cloud from the data stored in the data frame “df_fDist”.
Word cloud is a novelty visual representation of text data, typically used to depict keyword metadata (tags) on websites or to visualize free form text. Tags are usually single words, and the importance of each tag is shown with font size or color.
wordcloudConvertDF = pandD.set_index('Keywords').T.to_dict('records')
wordcloud = WordCloud(width=800, height=500, random_state=21, max_font_size=100, relative_scaling=0.5, colormap='Dark2').generate_from_frequencies(dict(*wordcloudConvertDF))
plt.figure(figsize=(14, 10))
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis('off')
plt.show()
Word cloud
So we just did sentiment analysis of Amazon Alexa by using NLTK in Apache Spark.
With Apache spark as a base, it’s a pretty straightforward process working with all this data. We just read the reviews into memory spread across a bunch of the nodes in the cluster and that is how we can do Natural language processing in a distributed manner.
Furthermore, if we go ahead and apply machine learning, a lot can be achieved by leveraging the power of Apache Spark.
That is all for this blog, please let me know for any suggestions/doubts in the comment section.