The article contains a detailed introduction to the Multi-armed Bandit problem along with various approaches to solve it and its Python implementation.
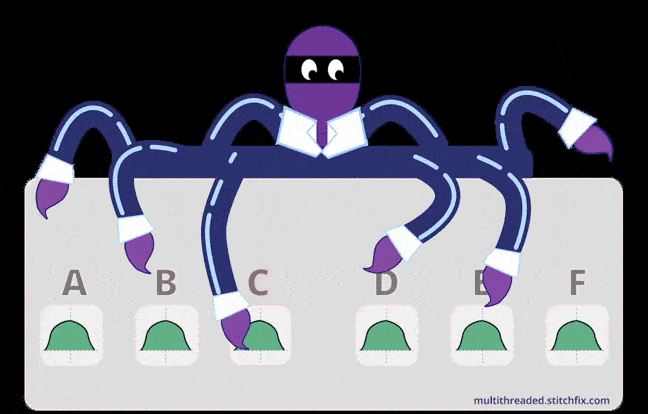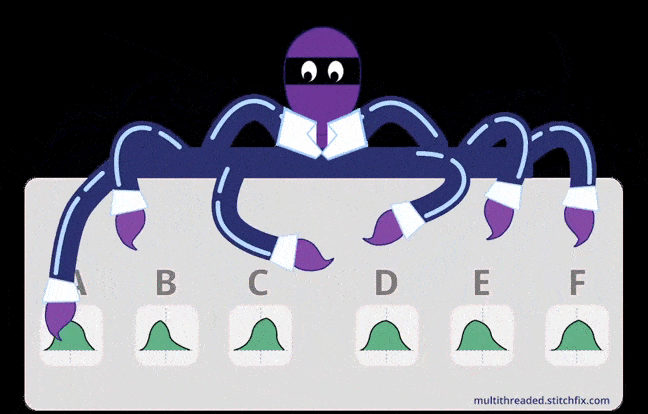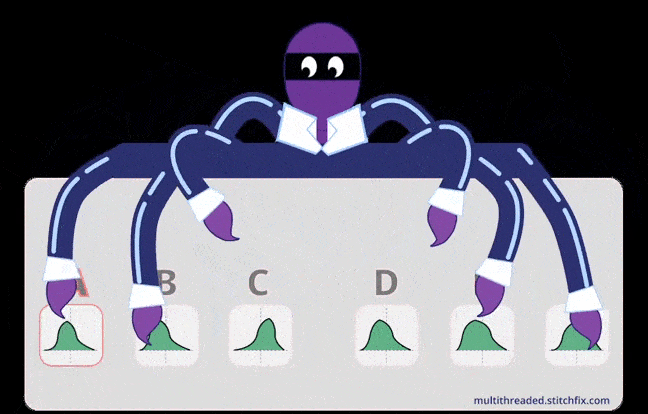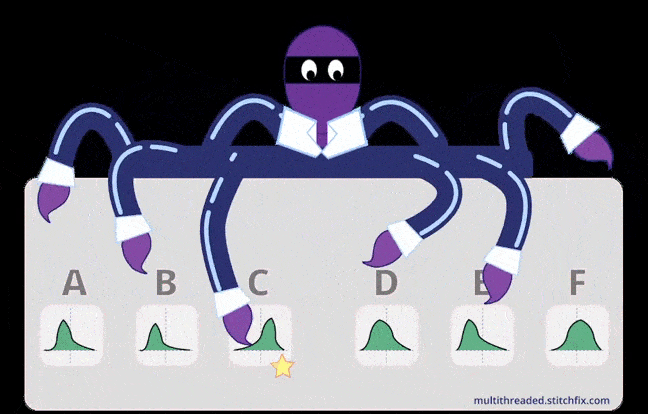
Credits: stitchfix
Introduction
If I ask you, Do you have a favorite restaurant in town? When you think of having lunch or dinner, you might just go to this place as you’re almost sure that you will get your favorite mouth-watery cuisine. But this means you’re missing out on the cuisines/dishes served by this place’s cross-town competitor.
And if you try out all the restaurants one by one, the probability of tasting the worse cuisine of your life would be pretty high! But then again, there’s a chance you’ll find an even better one. But what does all of this have to do with reinforcement learning?
Well, to answer this question, let's get started...
Reinforcement Learning and K-Armed Bandits
The one-armed bandit is a slang term for slot machines. Although the chances are slim, we know that spinning the one-armed bandit has a probability of winning. This means, given enough trials, we’ll win at some point. We just don’t know the probability distribution and can’t discover it with a limited number of trials.
Now imagine we’re in a casino, sitting in front of 10 different slot machines. Each one of the slot machines has a probability of winning. If we have some coins to play, which one do we choose? Do we spend all our chances on a single machine, or do we play on a combination of different machines?
Finding the optimal playing strategy to win the highest possible reward isn’t a trivial task. We’ll learn about strategies for solving the K-armed bandit in the following sections.
In reinforcement learning, an agent is interacting with the environment. It’s trying to find out the outcomes of available actions. Its ultimate goal is to maximize the reward at the end.
The k-armed bandit problem is a simplified reinforcement learning setting. There is only one state; we (the agent) sit in front of k slot machines. There are k actions: pulling one of the k distinct arms. The reward values of the actions are immediately available after taking an action:

k-armed bandit is a simple and powerful representation. Yet, it can’t model complex problems ignoring the consequences of previously taken actions.
To better model real-life problems, we introduce the “context”. The agent selects an action, given the context. In other words, the agent has a state, and taking action makes the agent transition between states and results in a reward. Simply put, context is the result of previously taken actions:

Still, the reward is immediate after choosing an action in the contextual bandit model, unlike real-world problems. Sometimes we get a reward after some time or after taking a series of actions. For example, even in simple games like tic-tac-toe, we receive the reward after making a series of moves when the game ends. Hence, contextual bandits are too simplified to model some problems:

Exploitation vs Exploration
Exploitation and exploration are two key concepts in the context of the multi-armed bandit problem, which is a classic problem in reinforcement learning. The goal of the problem is to repeatedly select one of several actions (known as "arms") in order to maximize the cumulative reward.
Exploitation refers to the strategy of selecting the arm with the highest estimated reward at each time step. This strategy is based on the assumption that the highest estimated reward is likely to be the true reward for that arm and that selecting it repeatedly will result in the highest cumulative reward over time. Exploitation is focused on exploiting the current knowledge of the reward distribution and maximizing the short-term reward.
Exploration, on the other hand, refers to the strategy of selecting arms at random or selecting arms with low estimated reward in order to gather more information about their true reward distribution. This strategy is based on the assumption that the estimated reward distribution may be incorrect and that gathering more information about the reward distribution of each arm will lead to better long-term performance. Exploration is focused on exploring the unknown aspects of the reward distribution in order to maximize the long-term reward.

exploitation and exploration. Credits
Balancing exploitation and exploration is a key challenge in the multi-armed bandit problem. If the agent focuses too much on exploitation, it may get stuck on a sub-optimal arm and miss out on the best arm. Conversely, if the agent focuses too much on exploration, it may waste time on low-reward arms and miss out on the cumulative reward from the best arm.
In summary, exploitation and exploration are two competing strategies for selecting arms in the multi-armed bandit problem. Balancing these strategies is essential to achieve the best overall performance.
What is a Multi-Armed Bandit(MAB)?
The Multi-Armed Bandit Problem (MAB) is a fundamental problem in the field of reinforcement learning and decision-making under uncertainty. The problem involves a gambler who has to choose among several slot machines (also called "one-armed bandits") with unknown payout probabilities. The gambler's objective is to maximize his or her total payout by choosing the best slot machine to play.

Slot Machine. Credits
The MAB problem is commonly used in various fields, such as clinical trials, online advertising, and recommendation systems. The MAB problem can be seen as a trade-off between exploration and exploitation. Exploration refers to the gambler trying out different slot machines to learn about their payout probabilities, while exploitation refers to the gambler sticking to the slot machine that has shown the highest payout probability so far.
A bandit is defined as someone who steals your money. A one-armed bandit is a simple slot machine wherein you insert a coin into the machine, pull a lever, and get an immediate reward. But why is it called a bandit? It turns out all casinos configure these slot machines in such a way that all gamblers end up losing money!

A multi-armed bandit is a complicated slot machine wherein instead of 1, there are several levers that a gambler can pull, with each lever giving a different return. The probability distribution for the reward corresponding to each lever is different and is unknown to the gambler.
ε-Greedy Algorithm
One of the most basic and commonly used algorithms for solving the MAB problem is the epsilon-greedy algorithm. This algorithm involves the gambler choosing the slot machine with the highest payout probability with probability 1-epsilon and choosing a random slot machine with probability epsilon. The value of epsilon determines the level of exploration. A high value of epsilon leads to more exploration, while a low value of epsilon leads to more exploitation.

The ε-greedy algorithm is a simple and effective way to balance exploration and exploitation in the multi-armed bandit problem. At each time step, the agent selects an arm with probability 1-ε, where ε is a small number between 0 and 1 that represents the agent's willingness to explore. With probability ε, the agent selects an arm at random, which encourages exploration of all arms, even those with initially low reward estimates.
Once an arm is selected, the agent receives a reward and updates its estimate of the reward distribution for that arm.
The ε-greedy algorithm then selects the arm with the highest estimated reward for the next time step, unless a random exploration is done.
In summary, the ε-greedy algorithm is a simple and effective approach for solving the multi-armed bandit problem by balancing the trade-off between exploration and exploitation. By exploring the low-reward arms with probability ε, it is able to find the best arm more quickly than a purely greedy strategy.
Upper Confidence Bounds(UCB)
Upper Confidence Bounds (UCB) is a popular algorithm for solving the multi-armed bandit problem. It is similar to the ε-greedy algorithm but uses a different strategy for balancing exploration and exploitation.
In UCB, the algorithm selects the arm with the highest upper confidence bound at each time step. The upper confidence bound is a measure of how uncertain the algorithm is about the reward distribution for that arm. It is calculated as follows:
UCB = estimated mean reward + exploration bonus
The exploration bonus is a function of the number of times the arm has been selected and the total number of times all arms have been selected. It is designed to encourage exploration of arms that have been selected less frequently, while still selecting arms with high estimated rewards.
The UCB algorithm starts by selecting each arm once to establish initial estimates of the reward distribution. It then selects the arm with the highest upper confidence bound at each subsequent time step. As more data is collected, the estimates of the reward distribution become more accurate and the algorithm becomes more confident in its arm selection.
With UCB, ‘Aₜ’, the action chosen at time step ‘t’, is given by:

where;
Qₜ(a) is the estimated value of action ‘a’ at time step ‘t’.
Nₜ(a) is the number of times that action ‘a’ has been selected, prior to time ‘t’.
‘c’ is a confidence value that controls the level of exploration.
One advantage of UCB over the ε-greedy algorithm is that it does not require a parameter to specify the level of exploration. The algorithm automatically adjusts the level of exploration based on the uncertainty of the reward distribution for each arm.
In summary, Upper Confidence Bounds (UCB) is an algorithm for solving the multi-armed bandit problem that balances exploration and exploitation by selecting the arm with the highest upper confidence bound at each time step. It is an effective algorithm for solving the problem and does not require a parameter to specify the level of exploration.
Thompson Sampling(The Bernoulli bandit)
A variant of the UCB algorithm is the Thompson Sampling algorithm. This algorithm involves the gambler choosing a slot machine based on a probability distribution that is updated based on the results of previous plays. The probability distribution is updated using Bayesian inference, which allows the gambler to incorporate new information about the payout probabilities of the slot machines.
In Thompson Sampling, the algorithm starts by assigning prior probability distributions to the reward distributions for each arm. These prior distributions represent the agent's initial beliefs about the reward distribution for each arm and can be updated as the algorithm gathers more data.
At each time step, the algorithm samples a reward distribution for each arm from its prior probability distribution. It then selects the arm with the highest sampled reward and receives a reward based on the true reward distribution for that arm. The algorithm updates its prior probability distribution for the selected arm based on the observed reward, which in turn affects the probability distribution for the next round.

The interpretation is simple. In the blue plot, we haven’t started playing, so the only thing we can say about the probability of a reward from the bandit is that it is uniform between 0 and 1. This is our initial guess for θk, our prior distribution. In the orange plot, we played two times and received two rewards, so we start moving probability mass to the right side of the plot, as we have evidence that the probability of getting a reward may be high. The distribution we get after updating our prior is the posterior distribution. In the green plot, we’ve played seven times and got two rewards, so our guess for θk is more biased towards the left-hand side.
The key advantage of Thompson Sampling is that it balances exploration and exploitation by considering the uncertainty of the reward distribution for each arm. If an arm has a high probability of being the best arm, it is likely to be exploited more frequently, while arms with low probabilities of being the best arm are more likely to be explored.
Compared to other algorithms such as Upper Confidence Bounds (UCB) and ε-greedy, Thompson Sampling has been shown to perform well in many cases, especially in settings where the rewards have complex, unknown distributions.
In summary, Thompson Sampling is a probabilistic algorithm for solving the multi-armed bandit problem that balances exploration and exploitation by selecting arms based on their probability of being the best arm. It is an effective algorithm for solving the problem, especially in situations where the reward distributions are complex or unknown.
Hoeffding’s Inequality
In the context of the multi-armed bandit problem, Hoeffding's Inequality provides a way to quantify the uncertainty associated with the estimated reward probabilities of each arm based on the observed rewards so far.
Let X1, ..., Xn be independent random variables such that ai <= Xi <= bi almost surely. Consider the sum of these random variables,
Sn = X1+X2+.....Xn
Then Hoeffding's theorem states that, for all t > 0,

Here E[Sn] is the expected value of Sn.
In simpler terms, it tells us that if we have a large number of independent observations of a random variable, the probability that the average of those observations deviates significantly from the true average decreases as the number of observations increases. This means that if we have a large sample size, we can be more confident that our sample average is close to the true average.
In the context of the multi-armed bandit problem, Hoeffding's Inequality is used to quantify the uncertainty associated with the estimated reward probabilities of each arm based on the observed rewards so far. It tells us that as we collect more data (i.e., more trials), the uncertainty in our estimates decreases and we can be more confident in our selection of the arm with the highest expected reward.
Difference between Multi-armed bandit (MAB) and A/B testing
Multi-armed bandit (MAB) and A/B testing are two commonly used approaches in experimental design and decision-making, but they differ in their underlying assumptions, goals, and trade-offs.

Multi-armed bandit vs A/B testing. Credits
In A/B testing, we typically divide the population into two or more groups (A and B) and randomly assign them to different treatments (e.g., different versions of a website or advertisement). We then measure some outcome of interest (e.g., click-through rates or conversion rates) and compare the results between the groups to determine which treatment is more effective. A/B testing assumes that we have a fixed budget and a fixed number of treatments to test, and the goal is to select the best treatment with the highest confidence level.
In contrast, multi-armed bandit (MAB) problems assume that we have a limited budget (e.g., limited time or resources) and a set of treatments (arms) with unknown reward distributions. The goal is to maximize the total reward obtained over time by sequentially selecting the best arm. Unlike A/B testing, MAB problems allow for learning and exploration, where the algorithm can try different arms to estimate their reward distributions and balance between exploiting the arms with the highest expected rewards and exploring new arms to reduce uncertainty.
The main trade-off between MAB and A/B testing is the balance between exploration and exploitation. A/B testing typically focuses on exploitation, where we want to make the best decision based on the available data, while MAB problems balance exploration and exploitation to maximize the total reward over time.
Regret Comparison of Action Selection Strategies
The figure below compares the worst-case bounds for some of the algorithms:

In most settings, epsilon-greedy is hard to beat. UCB and Thompson Sampling methods use exploration more effectively. Thompson sampling will be more stable, given enough trials. But, UCB is more tolerant of noisy data and converges more rapidly.
Depending on the problem at hand, a strategy can behave much better than the theoretical worst cases. Plotting the actual regret graphs of different algorithms might give different insights.
Implementing the K-Armed Bandit Problem in Python
Problem Statement
Suppose we have a company that runs an online advertising platform. The platform has 10 different ads, and the company wants to determine which ad generates the most clicks. To do this, they will use a multi-armed bandit algorithm.
Step 1: Import Libraries
The first step is to import the required libraries. We will use numpy for generating random numbers, and matplotlib for visualizing the results.
import numpy as np
import matplotlib.pyplot as pltStep 2: Define the Problem
We will define the problem by specifying the expected click-through rate (CTR) for each ad. We will assume that the CTR for each ad is normally distributed with a mean of 0.5 and a standard deviation of 0.1.
num_arms = 10
mean = 0.5
stddev = 0.1
arms = np.random.normal(mean, stddev, size=num_arms)Step 3: Define the Bandit Algorithm
We will use the epsilon-greedy algorithm to solve this problem. The epsilon-greedy algorithm is a simple algorithm that balances exploration and exploitation. It randomly selects a sub-optimal arm with probability epsilon and otherwise selects the arm with the highest estimated CTR.
class EpsilonGreedyBandit:
def __init__(self, num_arms, epsilon):
self.num_arms = num_arms
self.epsilon = epsilon
self.q_values = np.zeros(num_arms)
self.counts = np.zeros(num_arms)
def select_action(self):
if np.random.random() < self.epsilon:
return np.random.randint(self.num_arms)
else:
return np.argmax(self.q_values)
def update(self, action, reward):
self.counts[action] += 1
alpha = 1 / self.counts[action]
self.q_values[action] += alpha * (reward - self.q_values[action])Step 4: Run the Bandit Algorithm
We will run the bandit algorithm for a certain number of trials and record the rewards obtained on each trial.
num_trials = 1000
epsilon = 0.1
bandit = EpsilonGreedyBandit(num_arms=num_arms, epsilon=epsilon)
rewards = []
for i in range(num_trials):
action = bandit.select_action()
reward = np.random.binomial(1, arms[action])
bandit.update(action, reward)
rewards.append(reward)In each trial, we select an arm using the epsilon-greedy algorithm and then generate a reward by sampling from the Bernoulli distribution with a success probability equal to the CTR of the selected arm. We then update the estimated CTR for the selected arm using the update rule of the bandit algorithm.
Step 5: Visualize the Results
We can now print the Q-values and visualize the results by plotting the cumulative rewards obtained over time.
print("Q-values: ", bandit.q_values)
# Plot the estimated Q-values
plt.figure(figsize=[9, 5])
plt.bar(range(num_arms), bandit.q_values, color=(0.1, 0.1, 0.1, 0.1), edgecolor='green')
plt.xlabel('Arm')
plt.ylabel('Estimated Q-value')
plt.xticks(range(num_arms), ['Arm {}'.format(i) for i in range(num_arms)])
plt.ylim(0, 3.5)
plt.title('Estimated Q-values after 1000 trials')
plt.show()
Q-values: [0.47222222, 0.375, 0.86556604, 0.42857143, 0.625 0.375, 0.33333333, 0.35714286, 0.375, 0.42857143]
In the first graph, we can see the estimated Q-value for each arm after 1000 trials. The algorithm has learned that Arm 2 has the highest expected reward and has assigned the highest Q-value to it. The Q-values for the other arms are lower, reflecting their lower expected rewards.
Plot average reward obtained over time:
cumulative_rewards = np.cumsum(rewards)
average_rewards = cumulative_rewards / np.arange(1, num_trials + 1)
plt.figure(figsize=[9, 5])
plt.plot(average_rewards, color = 'green')
plt.xlabel('Trial')
plt.ylabel('Average Reward')
plt.title('Average Reward over Time')
plt.show()We can see that the algorithm starts by exploring different arms, and then gradually shifts towards exploiting the arm with the highest CTR(Arm 2), resulting in a higher average reward over time.

In the second graph, we can see the evolution of the average reward obtained over time. Initially, the algorithm tries different arms randomly, resulting in a low average reward. However, as the algorithm learns which arms have higher expected rewards, it starts selecting those arms more often, resulting in a higher average reward. We can see that the average reward increases over time and approaches the true expected reward for Arm 2, which is the arm with the highest expected reward.
Overall, these graphs show that the epsilon-greedy bandit algorithm is able to learn the expected rewards of each arm and select the arm with the highest expected reward over time.
Conclusion
In conclusion, the Multi-Armed Bandit Problem is an important problem in the field of reinforcement learning and decision-making under uncertainty. The problem involves a gambler who has to choose among several slot machines with unknown payout probabilities. Various algorithms have been developed to solve the MAB problem, each with its own advantages and disadvantages. The choice of algorithm depends on the specific problem at hand and the trade-off between exploration and exploitation.
Well, that's all for the article. Hope you liked reading it. Please share your thoughts/comments and the scope for improvements over LinkedIn.
Thanks for reading !!!

Bandit ;). Credits